Run Experiments on Powerful, On-Demand Compute Resources and Create Production-Ready Models in Seconds Using the Same Tools and Languages You Already Use
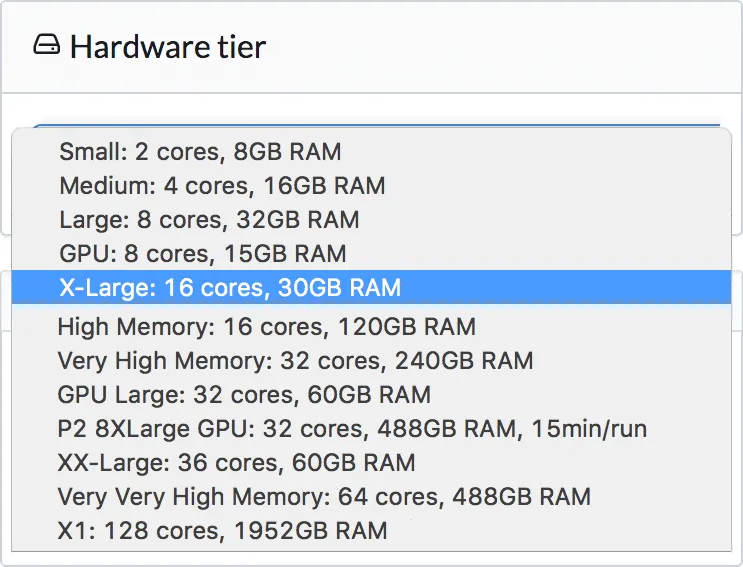
One Click, Unlimited Computing Power
Easily run your code on machines with up to 2TB of RAM and 100 cores, or specialized GPUs for deep learning. Run multiple experiments in parallel to iterate faster. Or run workloads over a Spark cluster with our first-class Spark support.
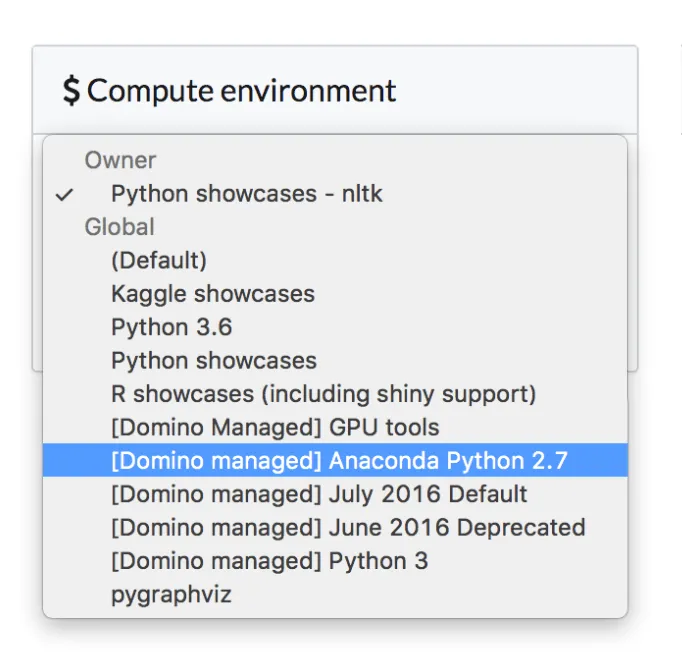
Stay Agile with Open Source
Modern data science teams use dozens of tools and multiple languages every day. Experimenting with new tools is critical, but can be a nightmare to reproduce. This limits innovation and hurts collaboration. Domino’s Compute Environments and Reproducibility Engine preserve the exact version of tools by running code in Docker containers. Need a custom package or tool? Domino lets you easily run anything that runs on Linux.
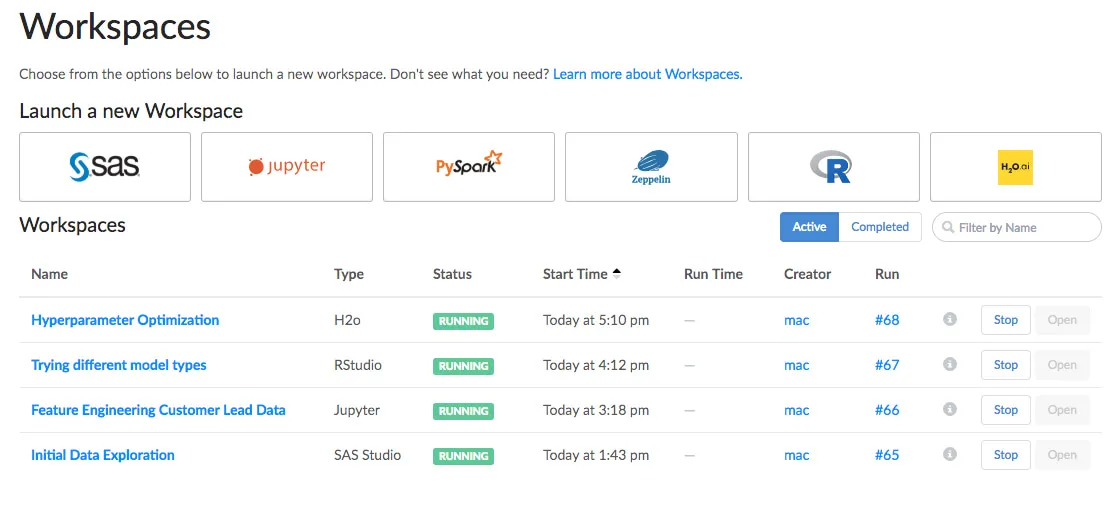
Explore and Iterate with Interactive Workspaces
With one click, Domino lets you spin up popular interactive tools like Jupyter, RStudio, Zeppelin, and more. And unlike your local machine, Domino lets you leverage automated version control, scalable hardware, and streamlined collaboration with colleagues.
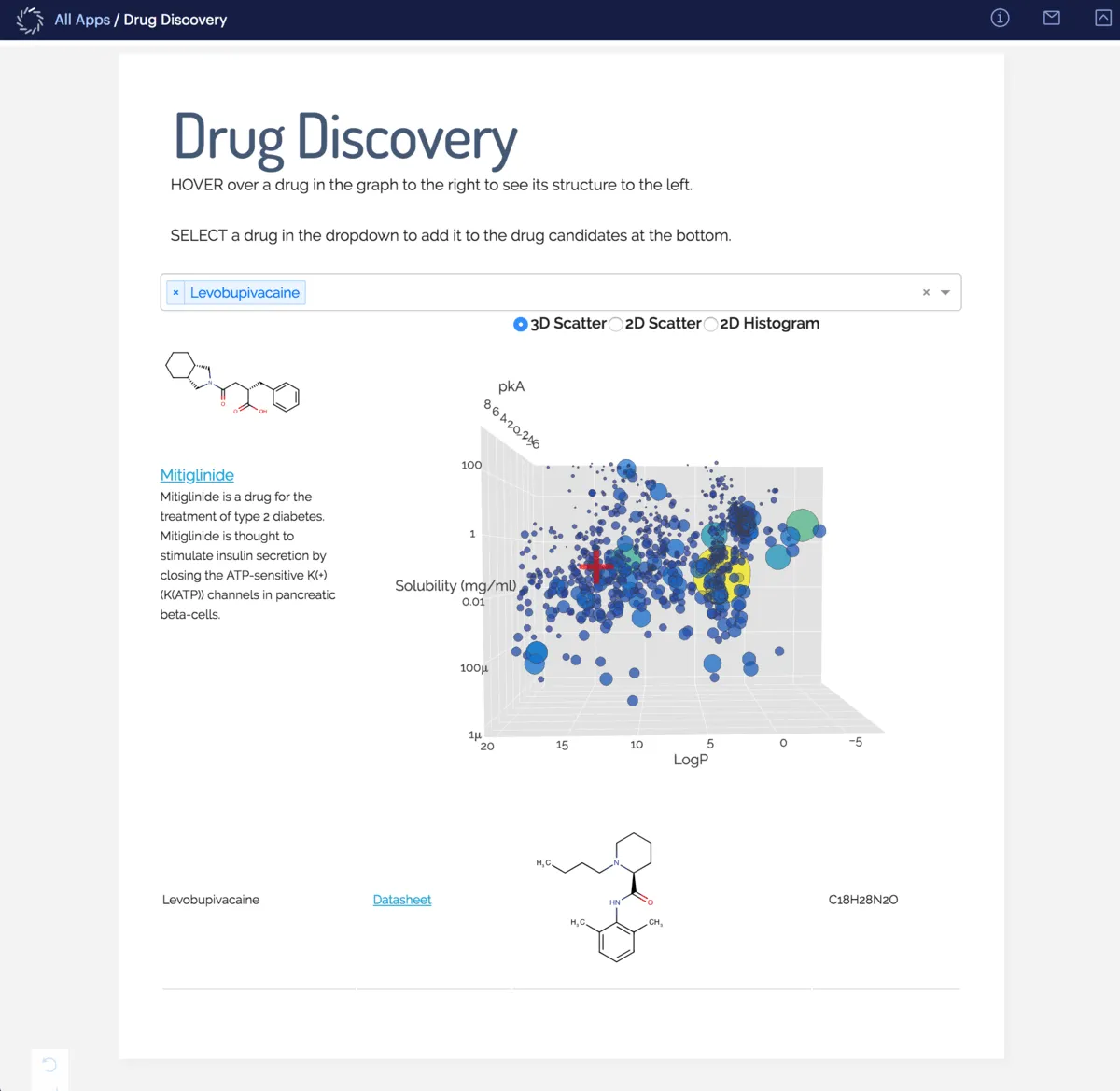
Deploy and Productionize
Building models is tough enough — deploying them shouldn’t be. Don't waste time translating results into other languages. Domino supports streamlined publishing of Python and R models as enterprise-grade REST APIs, complete with horizontal scalability. Need more user-facing tools? Domino hosts interactive Shiny and Flask apps and can also schedule recurring jobs for interactive report generation.