Become a Data Science Superhero
Suppose you find it tough getting access to the tools and technology you require to explore, experiment, and solve the big questions inside your organization. Or, can’t find and reuse past work so you always feel like you’re “reinventing the wheel” with each new project. If you’re tired of DevOps challenges and other technical issues keeping you from doing productive data science work, Enterprise MLOps is the solution for you.

Gain data science superpowers through Domino’s Enterprise MLOps platform. It has been designed and built by data scientists to help accelerate your research, give you the tools and other infrastructure you want to use at your fingertips, and eliminate the mundane manual tasks you need to perform when solving data science problems.
- Get the flexibility you need to use the tools that best suit your problem (e.g., Jupyter, RStudio, SAS, MATLAB, Spark) in an integrated environment that eliminates distractions so you can focus on solving problems.
- Collaborate at scale with other data scientists across your organization through knowledge sharing, experiment management, and reproducibility capabilities that supercharge your ability to work in a team.
- Gain the benefit of a single platform that provides consistent patterns and practices on how you access data, unlock the compute resources you require, and shift a model into production at the click of a button.
Unleash your data science superpowers
With Domino’s Enterprise MLOps platform you can overcome the DevOps and collaboration challenges that stand in the way of maximizing your productivity.
- Freedom to operate: self-service sandboxes give data scientists power and flexibility while enabling IT to centralize and govern infrastructure.
- Collaborative research at scale: reproducibility and collaboration capabilities allow data scientists to find and build on past work and freely collaborate to unlock new ideas and drive disruption.
- Deploy easily and with scale: teams use consistent and integrated workflows that increase model velocity and provide clear patterns and practices to reduce guesswork around deployment.
Domino is used by over 20 percent of the Fortune 100, saving them tens of millions in costs and unlocking research that has generated hundreds of millions of revenue.
Read more: Domino’s Enterprise MLOps Platform has a 542% ROI and three year $30M total value
Three challenges that make it difficult to scale data science
- Silos: Data Science grows organically in most organizations. This means fragmented infrastructure and disconnected teams that often have no visibility or understanding into what other data scientists are working on inside the business. This leads to wasted time duplicating efforts across multiple teams and means that learning and efficiencies are limited to data science teams rather than organization wide.
- Friction in the data science lifecycle: Data Scientists need freedom and flexibility to explore, experiment and ultimately solve their companies biggest challenges. In many organizations, getting consistent access to data, compute and production equipment means more time trying to solve technical problems than the business challenge at hand.
- Chaotic infrastructure: A wild west of data science tools and infrastructure forces data scientists to do DevOps work for much of their day. Collaboration and production often becomes stalled due to laptop-based code. And, when new packages and libraries become available, they’re either hard to integrate into most modern analytical infrastructure or lead to the formation of more disconnected “shadow IT” infrastructure.
Domino makes scaling data science easy and effective
Domino is an Enterprise MLOps platform that accelerates the process of developing and productionizing data science work, reduces cost of supporting data science teams, and mitigates regulatory risk.
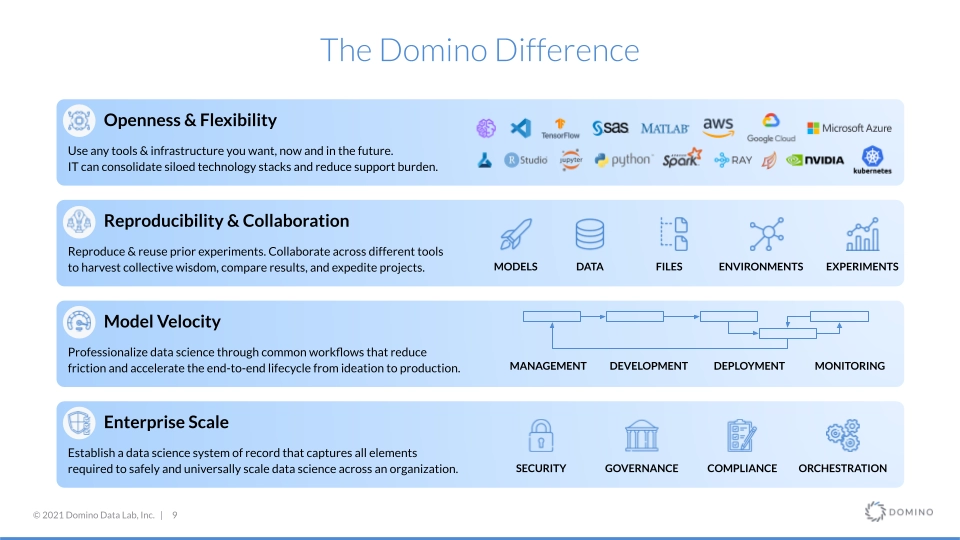
As a Data Scientist, you get access to the tools and infrastructure you need to be productive. Through our reproducibility engine, it’s easier than ever to create, define and track experiments over time and easily test new packages and libraries without creating technical debt. This means you’re spending less time wondering about how to gain access to data or solve technical issues, and more time solving business problems that generate real value for your stakeholders.