
Machine Learning Operations (MLOps) is a relatively new arrival to the world of data science. Barely five years old, it has already become viewed as a critical requirement for organizations in just about every industry and business sector that want to become model driven by weaving data science models into the core fabric of their business.
However, organizations are finding that implementing MLOps at the enterprise level is a much more complex problem than just implementing MLOps for a few models or a single team. Scaling data science and MLOps practices swiftly, safely, and successfully across an enterprise requires a broader version of MLOps that encompasses the entire data science lifecycle and meets the requirements of various teams both now and in the future. Enterprise MLOps is a new, robust category of MLOps that solves this problem.
Enterprise MLOps is a system of processes for the end-to-end data science lifecycle at scale. It provides a venue for data scientists, engineers and other IT professionals, to efficiently work together with enabling technology on the development, deployment, monitoring, and ongoing management of machine learning (ML) models.
It allows organizations to quickly and efficiently scale data science and MLOps practices across the entire organization, without sacrificing safety or quality. Enterprise MLOps is specifically designed for large-scale production environments where security, governance, and compliance are critical.

Analyst Study
Until a decade ago, the majority of work done in machine learning (ML) was experimental due to limitations in compute power. As it became practical to process vast amounts of data, those companies that were able to transition experimental ML models into production reaped huge rewards – but these successes were exceptions, not the norm.
The majority of projects stumble when models are transitioned from the data scientists to the production engineers for a wide variety of reasons including the need to recode models into a different languages for deployment (e.g. Python/R vs Java), inability to recreate the data used for training in production, and no standardization in the deployment processes.
This is because the majority of companies are still using what Deloitte describes as an "artisanal" approach to ML development and deployment. This lack of scalable patterns and practices delay value from data science. This is borne out by the results of a recent survey by DataIQ where one-third of respondents reported that it took months to get models into production. Visibility into project projects is also limited, with over 45 precent of respondents providing no or periodic updates. In another survey, 47 percent of ML projects never get out of the testing phase. Of those that do, another 28 percent failanyway.
To overcome these challenges the data science community looked to DevOps (or Development Operations) from the software engineering field for inspiration. Many of the concepts focusing on shortening development time, and increasing speed and quality were adopted. However, because data science and application development produce very different products, a new practice, MLOps, was born.

To understand why DevOps doesn't meet the needs of data science, it's important to understand the key differences between models and software applications. Both involve code and are saved as files, but the behavior of software is predetermined whereas model behavior changes over time.
They involve code, but they use different techniques and different tools than software engineering. Unlike software, they feed on data as a critical input. They use more computationally intensive algorithms, so they benefit from scalable compute and specialized hardware like GPUs. And they leverage packages from a vibrant open source ecosystem that's innovating every day.
Data science is research — it's experimental and iterative and exploratory. You might try dozens or hundreds of ideas before getting something that works. Often you pick up where another team left off, with their work being a jumping-off point of discovery and innovation. To facilitate breakthroughs, data science teams need tools to test many ideas, organize and preserve that work, and search and discover it later.
Models make predictions based on the data they are fed. They have no a priori correct behavior — they can just have better or worse behavior when they're live in the real world. Unlike software which never needs retraining or updating unless the business process changes, models do. Model performance can change as the world changes around them, creating risk from unexpected or degraded behavior. So organizations need different ways to review, quality control, and continually monitor them in order to control risk.
There are four phases in the data science lifecycle:
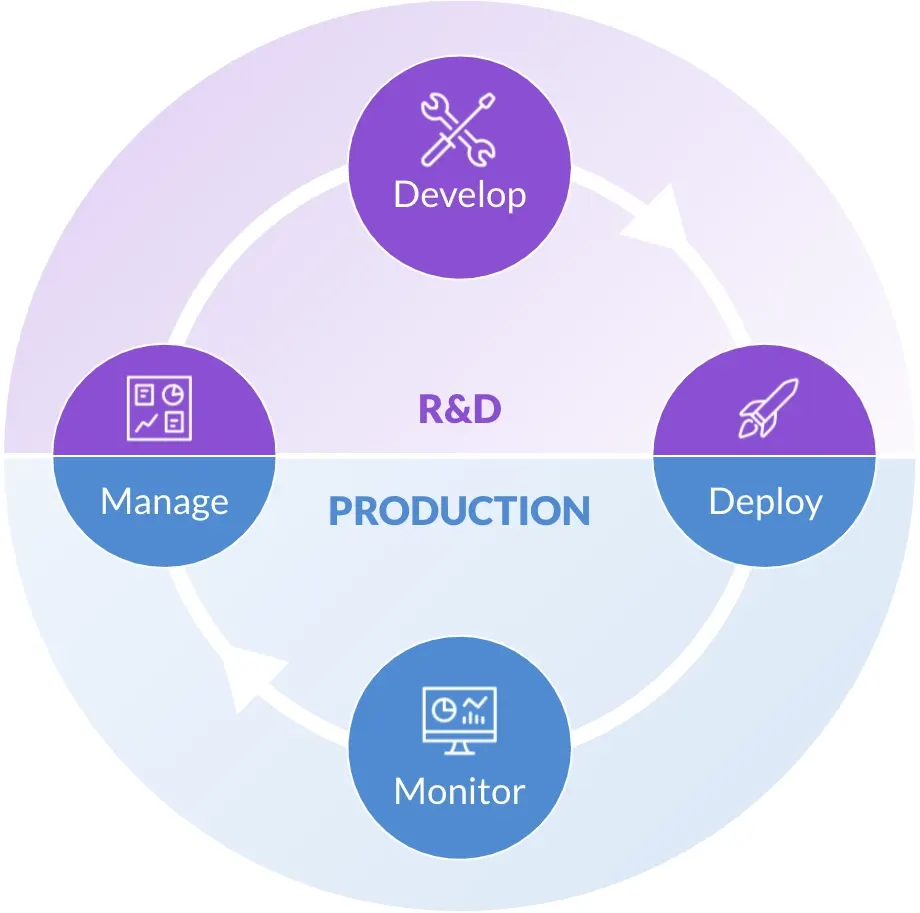
Today, most MLOps platforms just provide a stable platform for data science and data engineering typically focused on the production side of the data science lifecycle. They help prevent models from degrading due to unplanned or inconsistent refresh cycles, without the constant monitoring models would normally require. They're also used for testing and validating models.
Organizations have realized that even if they have implemented some level of MLOps, there are still things standing in the way of safely and universally scaling data science.
Tackling these three challenges requires a discipline that looks beyond the deployment portion of the data science lifecycle, which is where MLOps platforms have focused to date. It requires enterprise grade capabilities that allow projects to progress through the end-to-end data science lifecycle faster and provides for safely and universally scaling data science with the requisite security, governance, compliance, reproducibility, and auditability features. For these reasons, leading organizations are adopting Enterprise MLOps practices and enabling platforms.
An Enterprise MLOps platform needs to serve the requirements of all of the different members of the MLOps team, the organization's management, its workflows and lifecycles, and the continued growth of the organization as a whole. Enterprise MLOps capabilities can be thought of in two ways: tooling enhancements and process transformations.
Tooling enhancement capabilities include:
These capabilities dramatically increase productivity for data science and IT teams as well as provide storage and organization of all data science artifacts including data sources, data sets and algorithms for reproducibility and reusability. They allow IT to manage infrastructure and costs, govern and secure technology and data, as well as enable data scientists to self-serve the tools and infrastructure they need.
Process transformation capabilities include:
These capabilities are what allow organizations to safely and universally scale data science by making the most efficient use of resources, building on prior work, providing context and enhancing learning loops. Everyone uses consistent patterns and practices regardless of how or where the model was developed. All together they eliminate manual, inefficient workflows across all the activities of the data science lifecycle creating momentum that increases model quality, reduces the time required to deploy successful models from months to weeks, or days, and instantly notifies of changes in model performance so models can be quickly retrained or replaced.
Everyone learns from the successes and failures. Collaboration also includes engaging with the business in a non technical manner so they can understand the projects and outcomes. Finally, data science leaders can easily manage workloads and track project progress, impact and cost.
When these tooling and process transformation capabilities are all available, an Enterprise MLOps platform optimizes the throughput across the data science lifecycle, driving more models from development into production faster, while keeping them at peak performance and providing the tools and knowledge needed to repeat the cycle again.

When properly scoped an Enterprise MLOps platform supports the needs of everyone involved in the data science lifecycle. While the composition of any Enterprise MLOps team is going to vary from one organization to another, most members take on any of seven different roles:
Data Scientist: Often seen as the central player in any MLOps team, the Data Scientist is responsible for analyzing and processing data. They build and test the ML models and then send the models to the production unit. In some enterprises, they are also responsible for monitoring the performance of models once they are put into production.
Data Analyst: The data analyst works in coordination with product managers and the business unit to uncover insights from user data. They typically specialize in different types of tasks, such as marketing analysis, financial analysis, or risk analysis. Many have quantitative skills comparable to those of data scientists while others can be classified as citizen data scientists that have some knowledge of what needs to be done, but lack the coding skills and statistical background to work alone as data scientists do.
Data Engineer: The Data Engineer manages how the data is collected, processed, and stored to be imported and exported from the software reliably. They may have expertise in specific areas, like SQL databases, cloud platforms, as well as particular distribution systems, data structures, or algorithms. They are often vital in operationalizing data science results.
DevOps Engineer: The DevOps engineer provides data scientists and other roles with access to the specialized tools and infrastructure (e.g., storage, distributed compute, GPUs, etc.) they need across the data science lifecycle. They develop the methodologies to balance unique data science requirements with those of the rest of the business to provide integration with existing processes and CI/CD pipelines.
ML Architect: The ML Architect develops the strategies, blueprints and processes for MLOps to be used, while identifying any risks inherent in the life cycle. They identify and evaluate the best tools and assemble the team of engineers and developers to work on it. Throughout the project life cycle, they oversee MLOps processes. They unify the work of data scientists, data engineers, and software developers.
Software Developers: The Software Developer works with data engineers and data scientists, focusing on the productionalization of ML models and the supporting infrastructure. They develop solutions based on the ML architect's blueprints, selecting and building necessary tools and implementing risk mitigation strategies
Domain Expert/Business Translator: A Domain Experts/Business Translator has deep in-depth knowledge of business domains and processes. They help the technical team understand what is possible and how to frame the business problem into an ML problem. They help the business team understand the value offered by models and how to use them. They can be instrumental in any phase where a deeper understanding of the data is crucial.
The Domino Enterprise MLOps platform is feature-rich and designed to handle the needs of model-driven organizations using state-of-the-art data science tools and algorithms.
There are five main components of the Domino platform that interact seamlessly to support the full data science lifecycle.
The Knowledge Center is all about tracking and managing work in a central repository of key learnings. This is where users go to find, reuse, reproduce, and discuss work in a highly collaborative environment. Data science leaders can set goals for their team and manage the individual work products they're delivering to make overseeing the end-to-end data science process a lot more efficient.
The Workbench is the notebook-based environment where data scientists go to do their R&D and experimentation. Durable Workspaces give data scientists self-serve access to all of the tools and infrastructure they need to run, track, and compare experiments.
Launchpad is where we deliver on the "last mile" – getting models into production so they can create business value and impact. Many times this takes the form of an API that can be embedded into an existing system, or, as an App so business users can interact with the underlying model.
Model Monitor provides the ability to monitor all of the models in production across the company, and automatically detect when they need to be updated or replaced. It also is where users can assess business impact.
This all sits on top of a scalable and robust Enterprise Infrastructure Foundation that's based on Kubernetes. This is the core technology that allows data scientists to orchestrate infrastructure (including CPUs, GPUs, and distributed compute), and manage the packages and environments that support model development and reproducibility at any point in the future.
Customers who have adopted Domino's Enterprise MLOps platform consistently point to four areas where it drives value in their organization, allowing them to scale data science:
Domino supports the broadest ecosystem of open-source and commercial tools and infrastructure. Data scientists have self-serve access to their preferred IDEs, languages, and packages so they can focus on data science, not infrastructure. It also allows IT to consolidate different tools onto a single platform – reducing costs and support burden as well as providing governance across a wide variety of tools, packages, etc.
Disparate tools, teams, and all types of data science artifacts (including code, package versions, parameters, and more) are automatically tracked and integrated to establish full visibility, repeatability, and reproducibility at any time across the end-to-end lifecycle of every use case. Teams using different tools can seamlessly collaborate on a project, with the ability to leverage valuable insights and harvest a flow of collective wisdom.
Domino supports the full, end-to-end lifecycle from ideation to production – explore data, train models, validate, deploy, monitor, and repeat – in a single platform. Domino enables companies to professionalize their data science through common patterns and practices, with workflows that reduce friction and accelerate the lifecycle within each step and across key transitions, so all people involved in data science can maximize their productivity and the impact of their work.
While disparate data science teams are free to use their preferred tools, packages, and infrastructure, all aspects of their work are centralized and orchestrated through Domino. Users can onboard quickly, find previous work easily, collaborate effectively, and reproduce experiments seamlessly. Domino provides the security, governance, compliance, and all of the other elements that are required to scale data science safely and universally across an organization
In just a few short years, data science has brought us self-driving cars, risk analysis engines, Alpha Go, movie recommendation engines and even a photorealistic painting app. Where data science takes us from here is anyone's guess (specifically, an innovative and well-researched guess).
The companies that scale ML innovation over the next decade will be those that are model-driven, making money on their projects, building on each subsequent success, learning faster, developing more efficiently, reducing costs and minimizing poor outcomes.
Does your company strive to become model driven? Work with Domino Data Lab to ensure your company's success. To see the Domino Enterprise MLOps Platform in action, you can watch a demo or try it for yourself with a free trial.
